Analyzing the Linux Kernel in Userland with AFL and KLEE

Title image:
AFL: Creative Commons Attribution 3.0 Unported
Tux: By lewing@isc.tamu.edu
KLEE: Creative Commons Attribution 3.0 Unported
AFL: Creative Commons Attribution 3.0 Unported
Tux: By lewing@isc.tamu.edu
KLEE: Creative Commons Attribution 3.0 Unported
Analyzing the Linux Kernel in Userland with AFL and KLEE
At GRIMM we do a lot of vulnerability research and one of our favorite techniques for finding bugs in software is to repurpose or extend security tools from one area of research to another. One great example of this is when Juwei Lin and Lilang Wu ported syzkaller, the popular Linux kernel fuzzer, to macOS. Their research undercovered several bugs in the macOS kernel, including two that they were able to exploit to perform a local privilege escalation.
As part of a side project here at GRIMM, we’ve been analyzing the RHEL 7.7 kernel. In order to help analyze the kernel, we modified several portions of the kernel to work with existing tools typically used in Linux userland vulnerability research. The Linux userland environment has a much wider range of tools available to help with vulnerability research than the Linux kernel. A previous blog post described some of these vulnerability research tools and how they fit into the vulnerability research process. This blog post describes these efforts and the resulting investigation into the issues discovered.
The materials for this blog post can be found on our GitHub repository here:
https://github.com/grimm-co/linuxklee
https://github.com/grimm-co/linuxklee
Picking Targets
While the majority of the kernel is too intermixed to port to a standalone userland program, there are subsections that only use a minimum number of kernel API calls. As such, we focused our efforts on only analyzing components that were easily ported to userland. Two easy targets for porting the code to userland were the Linux kernel’s ASN.1 parser and the inet_diag bytecode interpreter. The Linux kernel’s ASN.1 parser is used to parse X.509 certificates, PKCS7 crypt_grphic messages, and RSA keys. The inet_diag bytecode interpreter is used in the sock_diag subsystem to determine which sockets to gather information from. The user passes in a bytecode program via a netlink message, the Linux kernel validates the bytecode, and then runs it in a simple interpreter loop. GRIMM’s GitHub repository contains the code for each of the ported parsers, however this blog will only discuss the X.509 parser.
Porting these two components to userland was relatively straightforward. The kernel APIs used by the ASN.1 parser and inet_diag bytecode interpreter can be swapped for similar userland APIs, i.e. kmalloc becomes malloc, pr_debug becomes printf, etc. For simplicity, we choose to simply remove the multiprecision function calls rather than port the kernel Multi Precision Integers (MPI) library. The Linux kernel’s MPI library was originally taken from GnuPG, where it has already received a large amount of testing as part of OSS-Fuzz. After porting these components, we created test programs that would read a file and call the appropriate API functions.
AFL
AFL is a userland coverage-based fuzzer that has been used to find a large number of vulnerabilities in popular software. AFL instruments the target program to allow it to receive coverage-based feedback when fuzzing. This feedback substantially improves the functional coverage of the target program, increasing the likelihood that a vulnerable path is found. In order to test our ported libraries, we’ll use AFL. Additionally, we’ll use AFL’s deferred startup and persistence mode to substantially increase the fuzzing speed. AFL’s deferred startup mode allows the test program to startup and perform any initialization prior to beginning fuzzing. This allows the test program to only execute the initialization once prior to fuzzing, rather than before each input is tested. Deferred startup is implemented by calling the __AFL_INIT in the test program after the initialization has finished, as shown below in the X.509 certificate test program. AFL’s persistence mode allows a single instantiation of the test program to test multiple inputs without restarting, thus saving the cost of continually restarting the test program. Persistence mode is implemented by modifying the test program to continually read and test the input in a loop with the loop condition based on the __AFL_LOOP macro, as shown below.
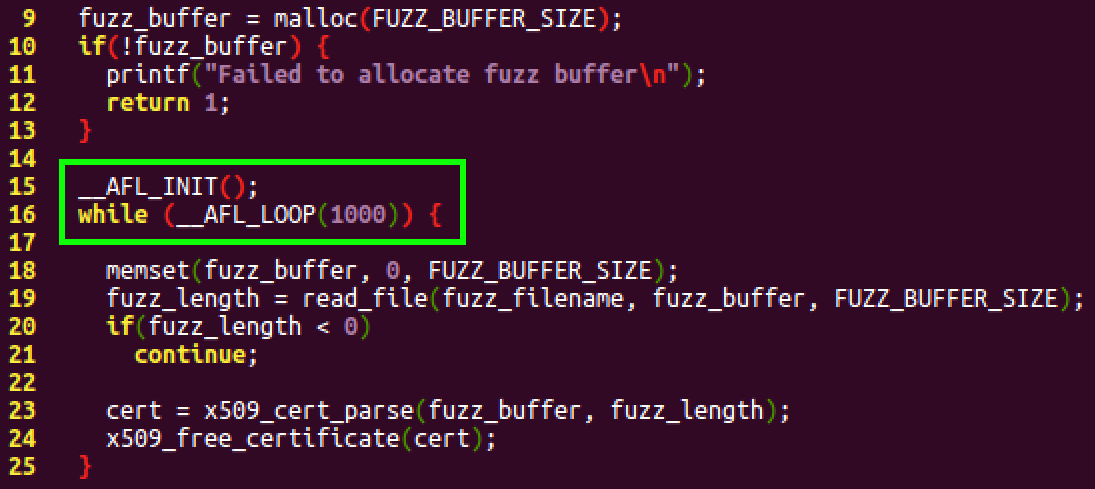

Figure 1. Modifications to the source code to enable AFL persistence and deferred mode
Once these small changes have been made to the test program, the next step is to compile the test program with afl-clang-fast and begin fuzzing with afl-fuzz, as shown below.
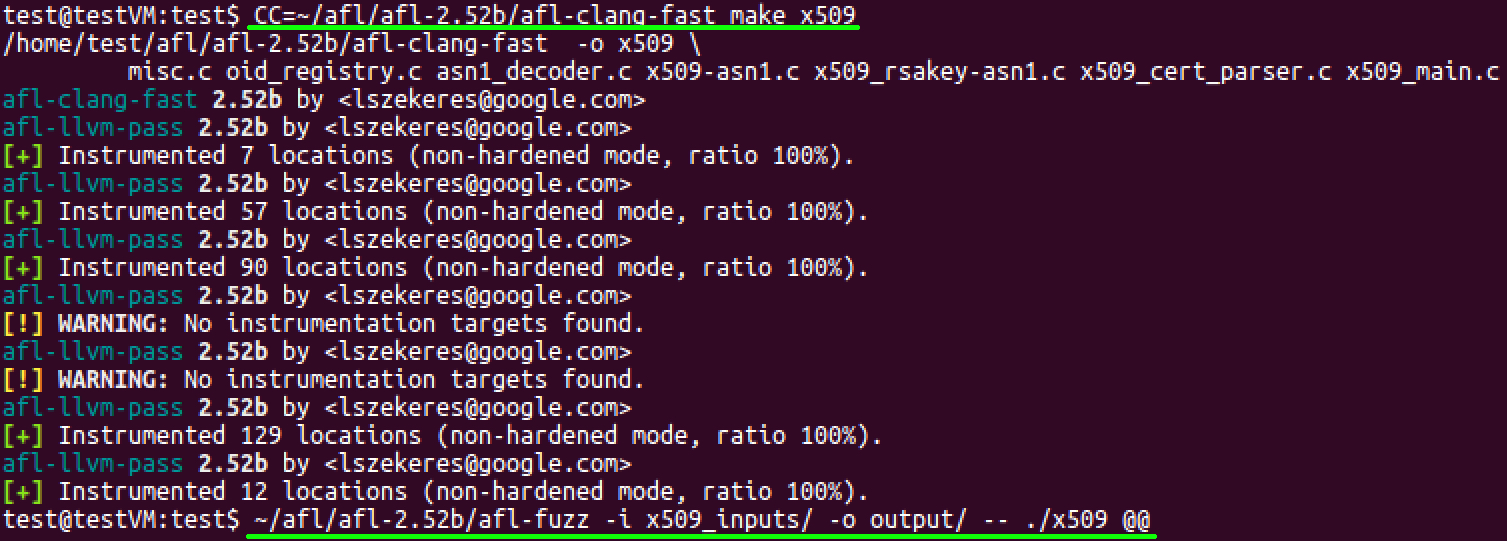

Figure 2. Compiling and running the test programs AFL
Unfortunately, after several days of fuzzing, AFL did not find any crashes within the X.509 parser. As such, we decided to move on to using KLEE to test the parser.
KLEE
KLEE is a symbolic virtual machine built on top of the LLVM compiler infrastructure. KLEE provides the means to symbolically execute our test program and look for any memory corruption bugs. In order for KLEE to know which bytes in memory are symbolic, we must call the KLEE API and specifically mark the memory as symbolic. In the X.509 test program, this is accomplished by replacing the call to read_file with a call to the klee_make_symbolic function. Additionally, our test program specifies that the input size is symbolic, so that KLEE can analyze test cases where the size of the input varies. In order to keep the input space tractable, the test program uses the klee_assume function to limit the size of the input.
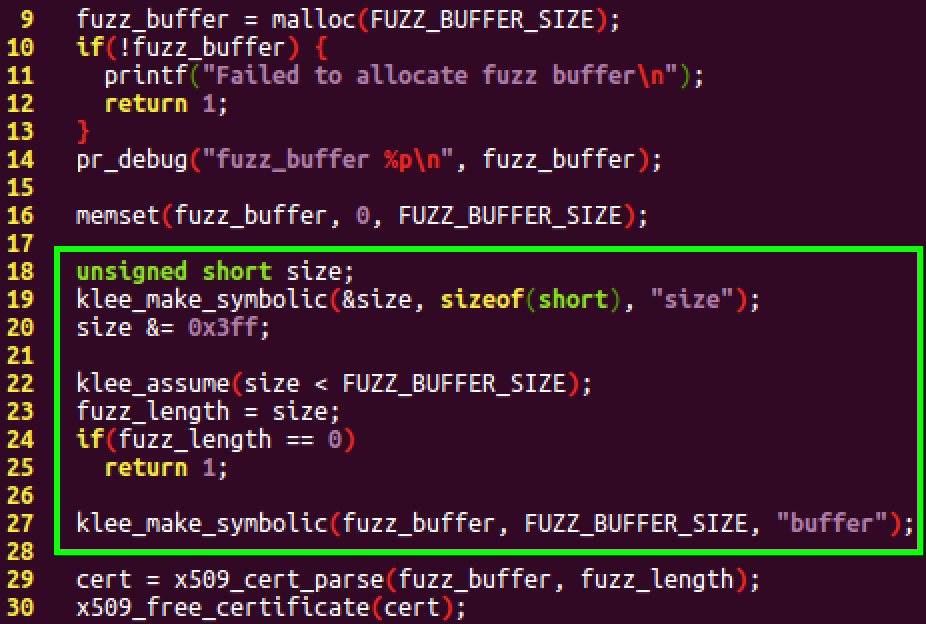

Figure 3. Modifications to the source code to allow KLEE to symbolically execute the test program
With the two symbolic variables specified, we can now execute the test program in KLEE. For simplicity of setup, we choose to run KLEE inside of Docker, as described in the KLEE documentation. Thus, running KLEE is as simple as starting the KLEE Docker container, compiling the X.509 test program to LLVM bytecode, and executing the klee utility.
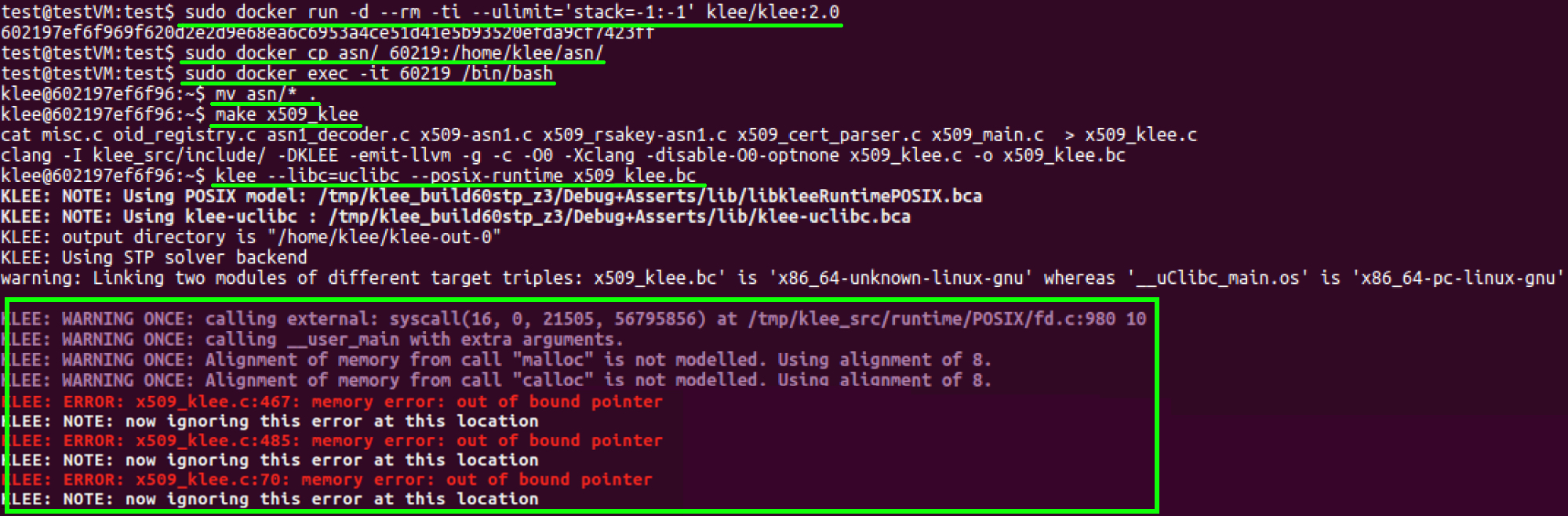

Figure 4. Compiling and symbolically executing the test program with KLEE
Root Cause Analysis
After a bit of time, KLEE produces errors indicating an out-of-bounds pointer is being used. We can look at the KLEE test case ptr.err output file to view a stack trace and an explanation of the error. This file indicates that the look_up_OID function is dereferencing a pointer that is not within a valid variable. Specifically, it is 1024 bytes past the malloc allocation for the fuzz_buffer variable, which is only 1024 bytes total. As such, it’s accessing memory past the end of this buffer.
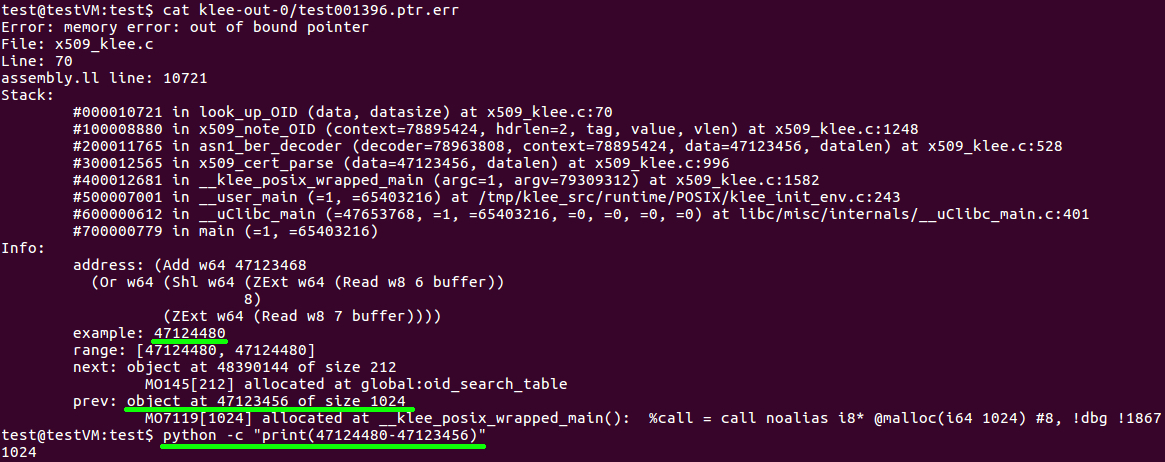

Figure 5. The bug report generated from KLEE’s symbolic execution
Using the ktest-tool python script, we can retrieve the inputs that caused the out-of-bounds memory reads. Furthermore, when we run the input in the x509_debug test program, as shown below, we can see that the x509_note_OID function is given a pointer at the end of the fuzz_buffer and incorrectly told that there is 1 byte available.
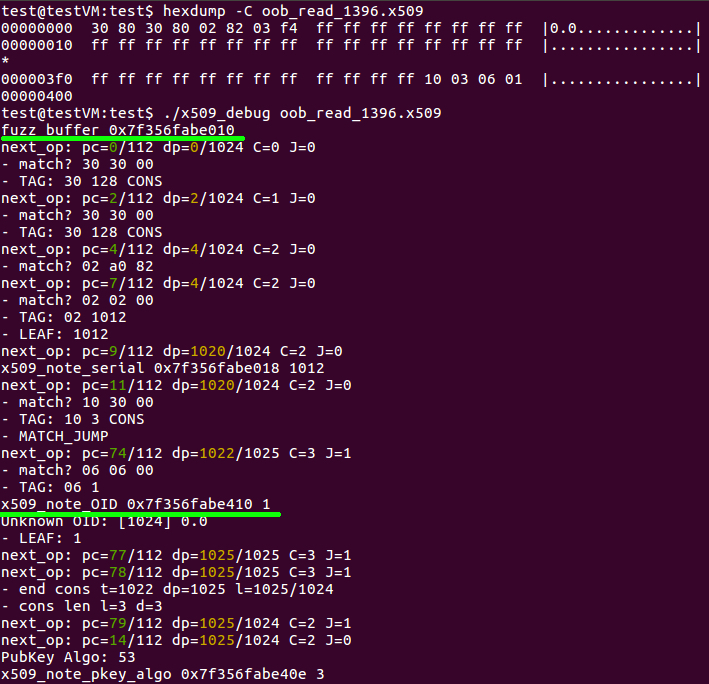

Figure 6. Using the ktest-tool, we can generate the erroneous input found via KLEE and analyze it
Looking through the ASN.1 decoder’s code, it quickly becomes clear that the length check is only performed when using a multi-byte ASN.1 length specification. When an item in the ASN.1 specification is longer than 127 bytes, the length is encoded into the following N bytes and the length field is used to specify how many bytes contain the input’s length. The top bit of the length field, 0x80, is set to indicate that the length is encoded using the multi-byte format. However, when the length is 127 bytes or less, the length can be directly encoded into the one-byte length field. In the ASN.1 decoder code shown below, we can see that the length check is only performed when the multi-byte format is used and the 0x80 bit is set in the length field. Thus, when the last bytes of the test input were 06 01, i.e. an Object Identifier (OID) with a length of 1, the length of the input was not validated to contain enough bytes for the OID and the x509_note_OID function was given an out-of-bounds pointer and incorrect size.
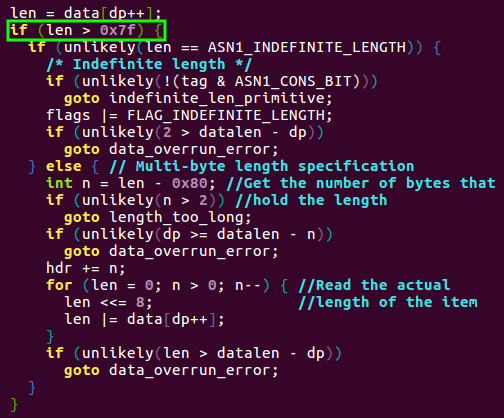

Figure 7. The erroneous code in the Linux kernel’s ASN.1 parser
Impact Analysis
Now that we’ve ascertained the root cause of the vulnerability, it’s time to determine what the impact of the vulnerability is. This vulnerability allows an attacker to cause data to be read past the end of an allocation. In the very rare case that the allocated data is at the end of a page and the adjacent page is not mapped, this may cause a kernel crash. In practice, this scenario is unlikely to occur. Rather, there is the potential to leak sensitive kernel memory to the attacker. However, due to checks which occur later in the parsing process, it’s unlikely that the parsing of an ASN.1 object could be completed successfully while triggering this vulnerability. As such, the attacker would be unable to retrieve the parsed item and directly obtain the leaked memory.
Another potential avenue for leaking the memory is via the print statements in the kernel. The x509_note_OID function will print any OIDs that it does not recognize. As such, an attacker could potentially learn the leaked memory by reading the kernel logs via the dmesg utility. However, the print statement in x509_note_OID is not enabled in the default configuration and cannot be enabled without root privileges. An example of enabling the print statements and triggering the vulnerability in the kernel to print the out of bounds bytes is shown below.


Figure 8. Example output of the bug being used to leak several bytes of kernel memory
Without an unprivileged way to retrieve the out-of-bounds bytes, this vulnerability is not very useful for an attacker.
Missing Fix
Having finished analyzing the vulnerability, we decided to determine which Linux distributions were also affected. However, we quickly discovered that this vulnerability had already been found and fixed in the mainline kernel in 2017. As such, my next question became, why did Red Hat not patch this vulnerability in their kernel? As of the time of writing, the ASN.1 decoder in the RHEL 7.7 kernel has not patched this vulnerability, despite RHEL 8.1 being patched and RHEL 7.7 still being supported. One possible explanation is that the original patch which fixed this vulnerability did not indicate that the bug was security relevant, and thus the RHEL developers did not include it in the RHEL 7 updates. Given the low impact of the vulnerability, this may be a reasonable decision.
However, this is not an uncommon scenario in the Linux kernel development process, and other higher impact information disclosure vulnerabilities have also not received a CVE in the past. In these cases, the downstream Red Hat developers may not identify the security relevance of the patch, and thus bugs can remain unpatched in the RHEL 7.7 kernel, despite fixes in RHEL 8.1, which is based on a later mainstream kernel.
Conclusion
This blog post detailed the process for analyzing the Linux kernel using userland tools. After porting the relevant portions of the kernel to userland, an out-of-bounds read vulnerability was detected using the KLEE symbolic execution engine. By analyzing this vulnerability, we determined that it had a low security impact and that it was fixed in the mainline kernel 2 years ago. However, this vulnerability has not been fixed in RHEL 7.7, despite a fix being available in RHEL 8.1, possibly due to the original patch developer not indicating the security relevance of the bug.
Want to join us and perform more analyses like this? We’re hiring. Need help finding or analyzing your bugs? Feel free to contact us.


